TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images [Part-1]

This is a 2-part series on end to end case study based TableNet research paper.
Table of Contents
- Introduction
- Business Objective
- Dataset Overview
- DL Problem and Performance Metric
- Data Pre-processing
- Exploratory Data Analysis
- Model Architecture
- Model Implementation
- Training
- Model Evaluation
- References
Introduction
With the increase use of mobile devices, customers tend to share documents as images rather than scanning them. These images are later processed manually to get important information stored in Tables. These tables can be of different sizes and structures. It is therefore expensive to get information in Tables from images.
With TableNet we will employ an end-to-end Deep learning architecture which will not only localize the Table in an image, but will also generate structure of Table by segmenting columns in that Table.
After detecting Table structure from the image, we will use Pytesseract OCR package to read the contents of the Table.
Business Objective
- The objective is to detect and output the structure of the table.
- Model should also output the Column structure of the table.
Data Overview
We will use both Marmot and Marmot Extended dataset for Table Recognition. The data is open-sourced by authors of this paper. With Marmot dataset we intend to collect Table bounding box coordinates and with extended version of this dataset we will collect the Column bounding box coordinates.
Original Marmot dataset contains both Chinese and English pages, for this Case study, we will only use English pages.
Marmot Dataset : download
Marmot Extended dataset : download

DL problem and Performance Metric
This task will be dealt using semantic segmentation by predicting pixel-wise regions of Table and columns in them
Metric : F1 Score to take both precision and recall into account, so that False Positives and False Negatives can be reduced.
Data Pre-Processing
Image data is in .bmp (bitmap image file) format and bounding box coordinates are in XML files following Pascal VOC format.
First we define 3 utility functions
- get_table_bbox() : This function will extract Table Coordinates using xml file from original marmot dataset and scale them w.r.t to new image shape
- get_col_bbox() : This function will extract Column Coordinates using xml file from extended marmot dataset and scale them w.r.t to new image shape, and if no table coordinates are returned from get_table_bbox() function, we will approximate them using column bounding boxes.
- create_mask() : This function takes in bounding boxes ( table / column) and creates mask with 1 channel. If no bounding boxes are given , it creates an empty mask.
Basic idea of preprocessing:
- Read image file, table_xml and column_xml.
- Resize image to (1024, 1024) and convert them to RGB ( if not already)
- Get both table and column bounding box
- Create mask for both
- Save Image and mask to disk
After converting processed_data to csv file.

Lets check the masks that were created based on table and column coordinates


Exploratory Data Analysis
- Lets start with the question : Do we have a balanced data ?
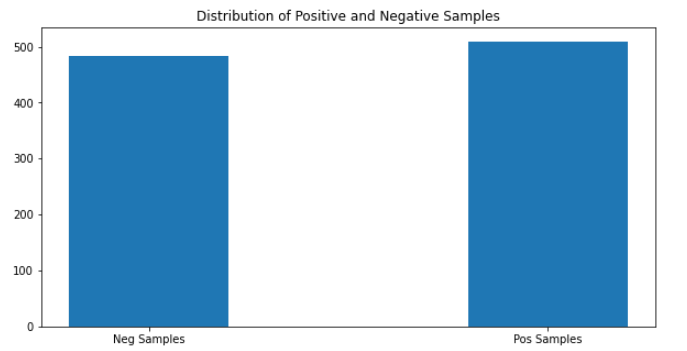
Positive data : 499 samples and Negative data : 494 samples
- Can there be Table without columns or vice-versa ?
Images with no tables but columns : 0
Images with tables but no columns : 5
Examples:


- What is the distribution of height and width of Image before resizing ?


Height of most images are between 1000–1100 and Width of most images are between 700–800.
- Average Tables and Columns in an Image ?


Apart from images with no Tables, most images contains only 1 table and at maximum 4 tables. Total Columns in an image (can have multiple tables in a page) ranges from 4–42, except for the case where there are no columns in a table.
- Average Height and Width of a Table ?


Height of tables ranges from 30–870, but most are between 50–300 and Width of tables ranges from 50–900, but common width is 400.
- Average Height and Width of a Column ?


Height of columns ranges from 10–880 showing a right skewed distribution and Width of columns ranges from 7–671 showing a right skewed distribution
Model Architecture
Authors used encoder — decoder style model ( semantic segmentation) , with pre-trained VGG19 as encoder . Two separate decoders are used for Table Mask and Column Mask.

The fully connected layers (layers after pool5) of VGG-19 are replaced with two (1x1) convolution layers. Each of these convolution layers (conv6) uses the ReLU activation followed by a dropout layer having probability of 0.8
Outputs from 3 pooling layers are concatenated with table decoder and column decoder, and then upscaled multiple times.
Training strategy:
- For first 500 epochs with batch size of 2, the table branch of the computational graph is computed twice, and then the column branch of the model is computed (2:1 ratio)
- Then model is trained till 5000 epochs with 1:1 training ratio between table decoder and column decoder.
Since Training for 5000 epochs was not feasible, I constrained the training epochs to 50–100, and tried different models for encoders.
Densenet121 worked best as encoder compared to VGG19 , ResNet-18 and EfficientNet. It is worth mentioning that performance of ResNet-18 and EfficientNet was almost close to DenseNet , but I chose the model based on Best F1 Score on Test data.
Model Implementation in Pytorch
Note: Below codes are snippets of actual code . For complete code, please refer my github repo.
To build any model in pytorch, we need
- Dataloader
Pytorch dataset: ImageFolder class takes df — dataframe as input which consists path of images, table masks and column masks. Every Image will be normalized and converted to pytorch tensor.
This dataset object is wrapped inside DataLoader class , which will return batches of data per iteration.
- Model
3 main components of the model —
→DenseNet121 Encoder block
→Table decoder Block
→Column decoder Block
Trainable Parameters

Input shape: (3, 1024, 1024)
Table Decoder Output Shape : ( 1, 1024, 1024)
Column Decoder Output Shape : ( 1, 1024, 1024)
- Loss function
BCEWithLogitsLoss() is used as loss here . This is a combination of Sigmoid + Binary Cross Entropy Loss. This will be applied to both column mask and Table mask separately.
- Train and Test functions
Train function takes data_loader , model, optimizer , loss and scaler as input and returns F1 Score, Accuracy, Precision , Recall and Loss for that epoch. Although keeping track of F1 Score is enough, but to monitor which one of precision and recall are misbehaving , I decided to monitor all of them.
optimizer used here is Adam with LR 0.0001 and Scaler is torch.cuda.amp.GradScaler which enables mixed precision calculation to improve training speed
Test function takes data_loader , model and loss as input and returns F1 Score, Accuracy, Precision , Recall and Loss for that epoch.
Model is trained for about 50 epochs with early stopping of 12 epochs and got pretty good F1 Score
Model Evaluation


As we can see F1 score of densenet121 is slightly better than others
Predictions




Now that we have trained our model, we can move on to the next stage.
Next Up,
- Part 2: Post EDA and OCR Predictions
If you want to check out whole code , please refer to my Github repo below.
You can connect with me on LinkedIn
